Project
Tapestry
A consortium approach to training frontier foundation models and sovereign derivatives.
Yann LeCun · Chief Science Advisor
AI Alliance launches Project Tapestry to build a collaborative foundation for open and sovereign AI.
The AI Alliance, a non-profit AI research and open-source technology coalition with more than 200 member organizations, introduces Project Tapestry — a new open-source platform for globally federated development of frontier AI models — preserving local control and long-term independence.
Today, open-weight AI models are everywhere. But open weights alone do not make pretraining participatory.

Built on advances in distributed training which have demonstrated that globally federated model development can match synchronous baselines, the project enables institutions, industries, and nations to co-train a shared open foundation model while retaining control of their data and the ability to build sovereign derivatives aligned to their own priorities.
The thesis is testable and the science is ready. What remains is coordination.
The time is now for frontier sovereign AI
Today, models with frontier performance are owned and controlled by a small number of organizations based in a few regions. Only a fraction of the world's data, compute infrastructure, and technical community are involved in frontier model development.
What if we could build a new global foundation model with this broader set of knowledge, resources, people and organizations working together — achieving performance no single organization could replicate, that every participating organization could build on?
Performance is the path to sovereignty
Tapestry brings together data, compute and talent from a global consortium to build the next frontier of foundation models — trained on a larger, more diverse corpus than ever before.
Frontier performance
A global foundation model system more performant than any other, while enabling sovereign derivatives owned and controlled by partners.
Sovereignty
A person, organization, or nation can own and control their AI, use it how they see fit, and retain the value they create with it — independence and agency.
Structural advantage
Consortium-managed access to data creates a structural advantage. Distributed ownership, sustainable funding, and mission-locked governance ensure trust.
Own your data, share in the model
Consortium model
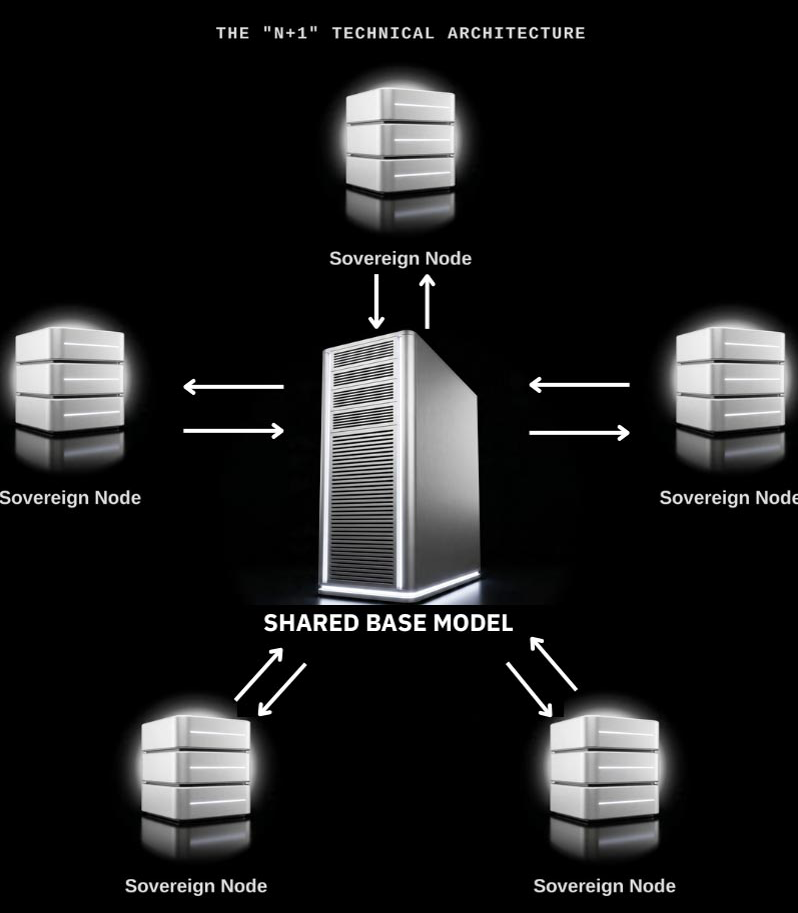
One base model, many owners
Partners keep full ownership of their data and compute — and the value they create with it. Every contribution makes a base model that all owners build on stronger.
Operating model
Decentralized contribution, centralized integration, trusted governance
The design principle behind Tapestry's operating model — contribution happens everywhere, technical integration happens at the core, and governance is trusted by everyone.
Decentralized contribution
Centralized technical integration
Globally trusted governance
Distributed training
Only the weights are shared
Data can be contributed privately to the core training corpus for base-model training only. Sensitive data is held back at the partner node and used locally to update weights — only the weights are shared.
Sovereign derivatives
Your model, fully owned
Any partner can create a derivative model of the base that they fully own and control — using the same infrastructure.
Globally Sourced Training Data
Training data sourced from partners around the world may become one of Tapestry's most important assets and the source of our differentiation. As a starting point we seek to catalog potential sources of training data from partners globally.
What can be contributed
- Public or private datasets
- Domain / industry data
- Language & cultural resources
- Government / public records where lawful
- Evaluation datasets & environments
- Preference & feedback data
What must be described
- Provenance & ownership
- License & use restrictions
- Privacy / PII status
- Quality & AI-readiness
- Geography & jurisdiction
- Permitted use (pre/post-training, evals, synthetic gen)
Benefits to contributors
- Recognition & contribution accounting
- Access to improved base models
- Right to create local derivatives
- Control over restricted data use
- Path to commercial & sovereign ROI
- Governance input
Metadata-first contribution — partners describe contributions by type and metadata; data stays local and raw corpora are never shipped.
Propose a dataset →Phase 0: First technical milestones
Specific early goals to validate hypotheses and de-risk scale-up.
Cultural alignment
Release and publish the first model re-aligned to 2+ cultures without core performance loss.
Distributed training
Demonstrate and open source the first multi-node weight update and aggregation framework; run experiments to understand scale-up requirements.
Training data catalog
Create a registry of metadata associated with candidate data sources available to the consortium.
Long-term roadmap
Progression between phases is gated by technical proof points, partner commitments, compute availability, data readiness, and funding thresholds.
Initial commitments
MOUs, initial sponsors, tech demos, data catalog prototype; formation steering committee.
● Active nowTraining platform v1
N-node training, local tuning, initial aggregation, first legal/data framework; initial governance & entity.
First base model
Small model from scratch, continued pretraining pipeline, first sovereign derivatives.
Early deployment
Industry/government use cases, larger runs, developer & partner ecosystem.
Frontier-scale effort
Contingent on compute, data, and capital thresholds.
Who should join
Tapestry is assembling its first contributors — the researchers, systems engineers, compute providers, governments, and institutions who will build the first sovereign federated training run.
- 01ML researchers working on distributed optimization, federated learning, or low-communication training
- 02Systems engineers with experience in large-scale GPU cluster orchestration
- 03Compute providers — cloud, sovereign cloud, or national HPC centers
- 04Government and policy leaders responsible for national AI strategy
- 05Universities and research labs with multilingual, domain-specific, or institutional datasets
Join us to build frontier sovereign AI
Path 01
Learn more / get involved
New to Tapestry? Tell us how you'd like to participate and we'll be in touch.
Path 02
Contribute
Explore the code, follow the work, and open issues or pull requests on the Tapestry repository.
Path 03
Propose data
Have a data source for the consortium? Tell us about it through the form.
Get involved
Tell us how you'd like to participate and we'll be in touch.