
The agents are here.
Capable coding agents and real-world deployments are finally turning years of hype into something practitioners can hold. The community has something real to work with.
But there is a quieter problem underneath all that momentum: we are sitting on a gold mine of evaluation and training data, and most of it is locked behind an engineering wall.
307 Benchmarks. Almost None of Them Portable.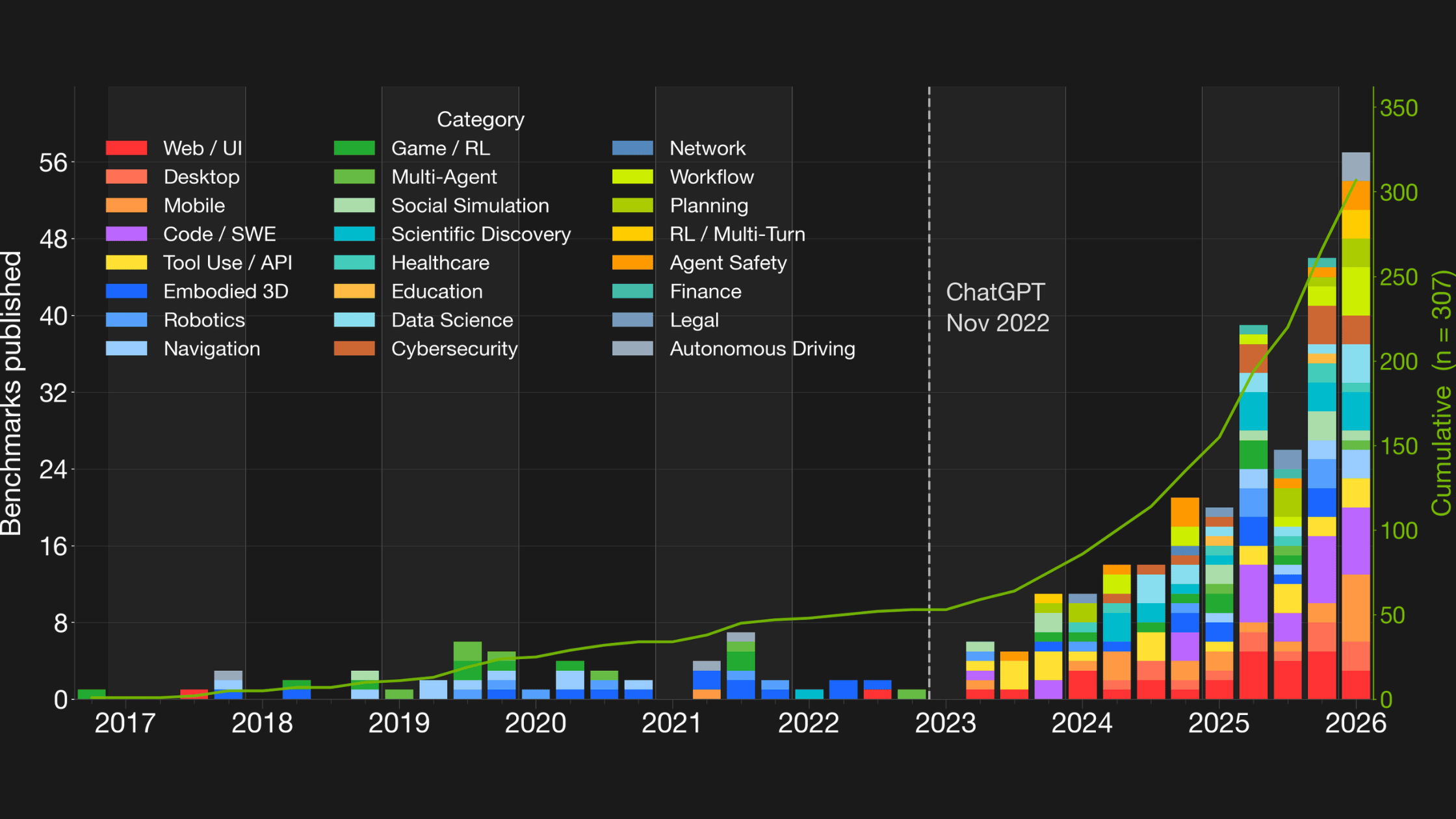
[The rise of agentic benchmarks: 307 cumulative through 2026]
The agentic benchmarks community has been extraordinarily productive. OSWorld, SWE-Bench, WebArena, TerminalBench, and hundreds of others have built rich, structured environments where agent behavior can be measured, filtered, and learned from. Today there are 307 published agentic benchmarks. By the end of 2026, forecasts put that number at 500 to 700.
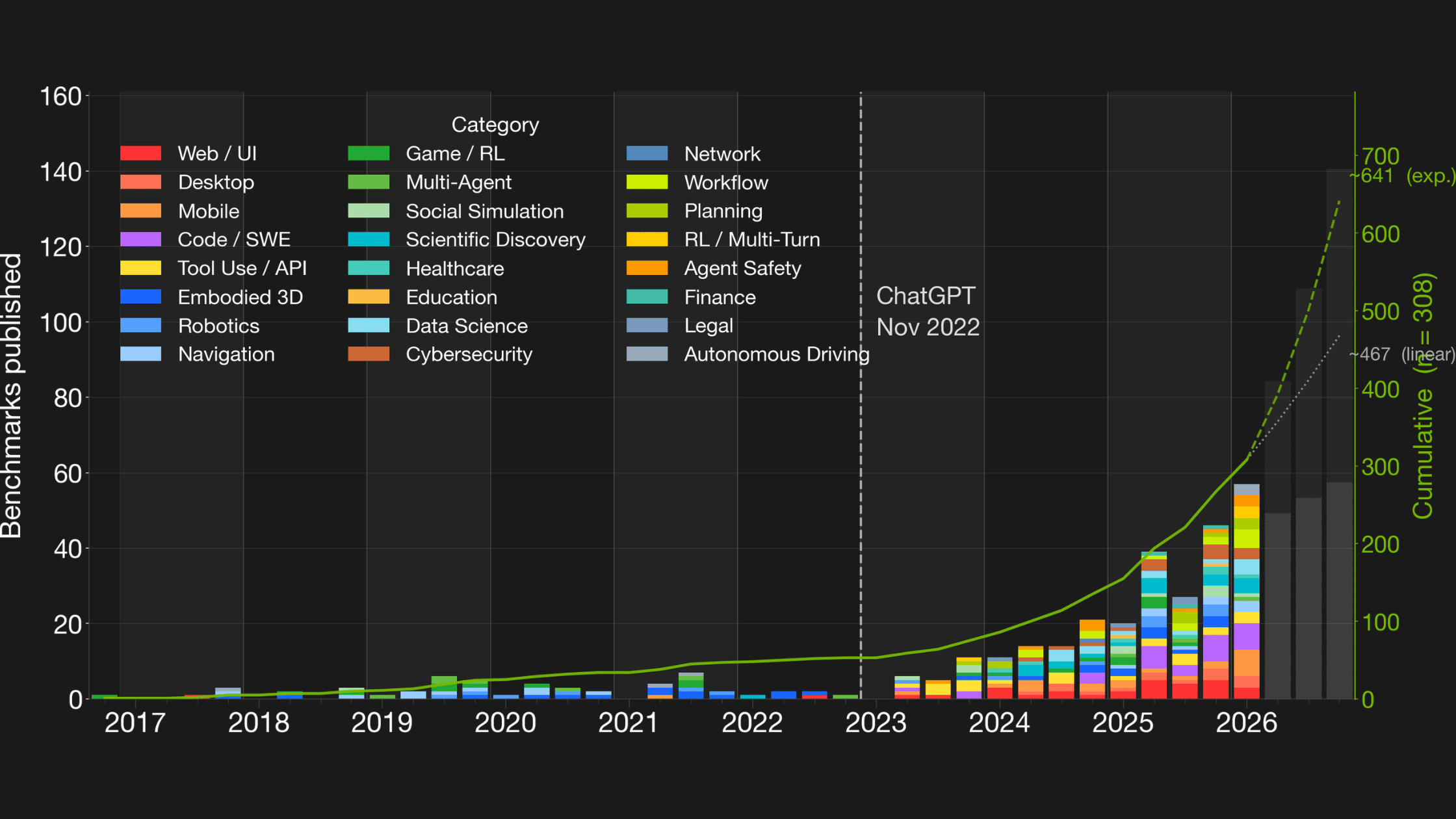
[Forecast: 500-700 agentic benchmarks by end of 2026]
Each one is a potential source of evaluation signal and post-training data. The kind of signal that is hard to fake and expensive to generate from scratch. Verified, grounded, structured.
The problem is access. Between a benchmark repository and an evaluation or training pipeline sits a wall of custom integration work.
N benchmarks times M platforms equals N times M connectors. Want to run OSWorld on your eval infrastructure? Someone has to write that integration. Want the same benchmark to also feed an RL training loop? Someone writes it again. Most of that engineering falls on researchers who had better things to do.
The Window to Standardize Is Now
The benchmark ecosystem is fragmented today, but the situation is still recoverable. At 307 benchmarks, the community can still move together. At 700, with years of incompatible tooling already in production, retrofitting becomes enormously expensive.
Standards succeed when they arrive before fragmentation locks in. HTTP arrived before every web server had its own wire protocol. CUBE is designed to do the same for agentic benchmarks, and GTC 2025 was a strong signal that the community is ready for this.
CUBE: Wrap It Once, Use It Everywhere
CUBE (Common Unified Benchmark Environments) is a minimal interface standard for agentic benchmarks. Wrap a benchmark once against the CUBE protocol, and it works across any CUBE-compatible platform, for evaluation, RL training, or data generation, on any infrastructure.
The key insight is separating *what* a benchmark needs from *how* that gets provisioned. A benchmark declares its requirements: a container, a VM, specific ports, a snapshot. The platform handles dispatch. Whether that means a laptop, an AWS cluster, or an HPC system is not the benchmark's problem anymore.
CUBE defines four levels of interface:
- Task: the core agent-environment interaction loop
- Benchmark: a collection of tasks with shared lifecycle management
- Package: resources shared across tasks, like a WebArena server
- Registry: benchmark discovery and filtering
This is not a platform. It is the protocol underneath. HTTP for benchmarks. Platforms like NeMo Gym, AgentBeats, Harbor, and OpenEnv compete on features. Benchmarks stay portable.
Built in the Open, Shaped by the Community
[CUBE standard](https://github.com/The-AI-Alliance/cube-standard) and [cube-harness](https://github.com/The-AI-Alliance/cube-harness) are Apache licensed and live in the AI Alliance GitHub. The [position paper] is on arXiv. The code is there today, with ten CUBE-compliant benchmarks already wrapped spanning software engineering, web navigation, and computer use. Integrations with major training and evaluation frameworks are in active development.
The project has drawn nearly 30 co-authors from Mila, McGill, IBM Research, Berkeley, CMU, Ohio State, HKU, and more, with advisory input from Graham Neubig, Siva Reddy, Dawn Song, Tao Yu, and Yu Su.
That breadth is not accidental. The AI Alliance exists to bring researchers, engineers, and domain experts across organizations to work on problems like this. CUBE is that mission in practice, a community standard built by exactly that kind of cross-institutional collaboration.
What Happens Next Is Up to the Community
CUBE is releasing early specifically because standards are most useful when shaped by the community before they calcify. If you maintain a benchmark, build evaluation infrastructure, or run large-scale RL training, your feedback shapes what CUBE becomes.
The lowest-friction way in is to [fill out this short form](https://forms.gle/DGxvw7ixY1wMB53Q9) to register your benchmark. No commitment required, whether you are the original author or just a frequent user who wants to see it wrapped.
If you want to go further, the fastest technical path is:
```sh
cube init my-bench # scaffold from the built-in template
cube test my-bench # run the compliance suite
```
Want deeper involvement in shaping the standard itself? The core team is accepting applications from researchers and engineers who want to influence the roadmap and get credit for what they build.
Apply here
Resources:
- CUBE standard: https://github.com/The-AI-Alliance/cube-standard
- CUBE harness: https://github.com/The-AI-Alliance/cube-harness
- Position paper: https://arxiv.org/abs/2603.15798
Lead architect of the standard: Alexandre Lacoste (ServiceNow AI Research)
Lead engineer of the implementation: Nicolas Gontier (ServiceNow AI Research)
Main institutions: ServiceNow Research, Silverstream.ai, NVIDIA
With advisory input from: Graham Neubig, Siva Reddy, Dawn Song, Tao Yu, Yu Su