
Discover Docling, the powerful open-source AI document processing tool developed by IBM Research and supported by the AI Alliance, designed for fast, local, and privacy-first workflows. With no reliance on cloud APIs, Docling offers high-quality outputs and flexible licensing, making it ideal for enterprise and research use. Now enhanced by Hugging Face’s SmolVLM models, SmolDocling brings lightweight, multimodal AI to complex document layouts—handling code, charts, tables, and more with precision. Join the growing open-source community transforming document AI and contribute to the future of trusted, efficient, and collaborative AI innovation.
Original Interview from January 2025
When you need document processing that is seamless, efficient, and entirely controlled by you-free of restrictions or reliance on external API, Docling is the answer. Docling is an open-source Python package designed to prepare documents for GenAI models with precision while not compromising speed.
As an affiliated project of the AI Alliance, Docling started as a project within IBM research and gained substantial traction. Since its release, Docling earned more than 25,000 stars on GitHub.
To get an idea of what Docling is and where to start watch our video!
So far, Docling offers: Local Processing – No cloud dependencies, ensuring data privacy High-Quality Output – Small yet powerful models for fast and accurate results Flexible Licensing – Designed to empower enterprise and community adoption
In the spirit of collaboration and innovation, we’re excited to see AI Alliance member Hugging Face partnering with IBM Research to enhance Docling’s capabilities. Hugging Face recently introduced two lightweight Vision Language Models, SmolVLM-256M and SmolVLM-500M. These highly efficient, multimodal models offer powerful vision and text understanding in a compact format, making them ideal for document processing, image captioning, and visual reasoning—key areas where Docling excels.
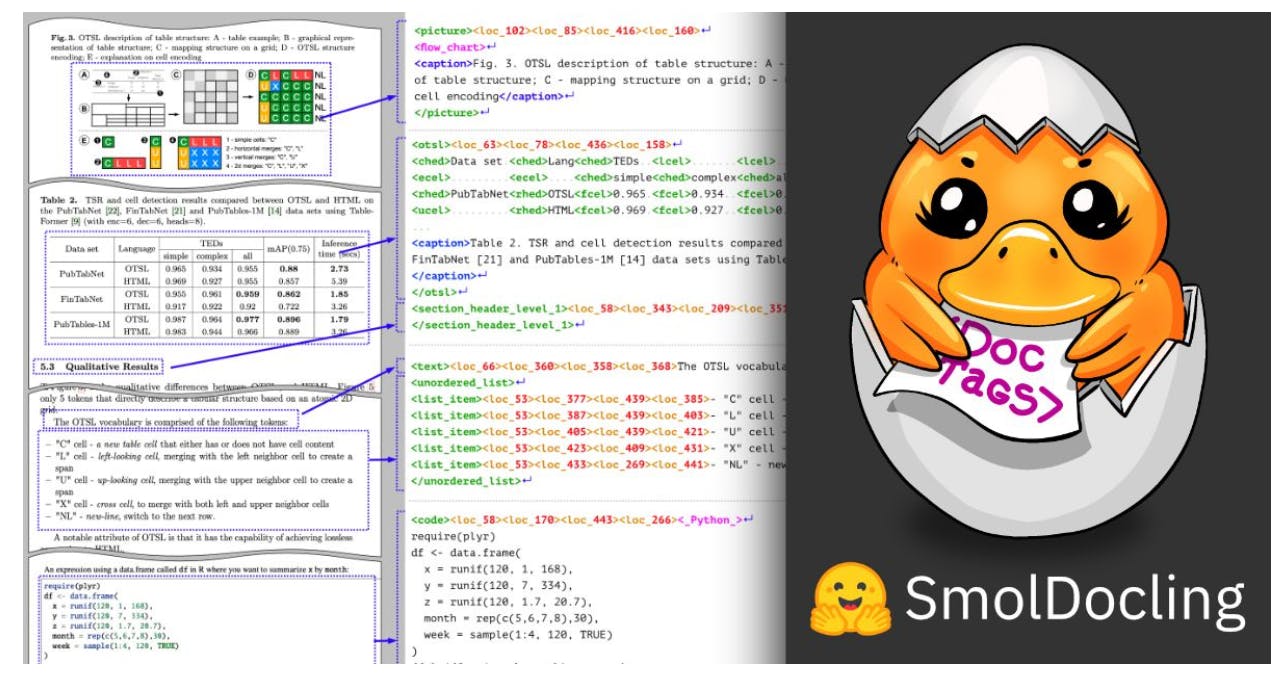
SmolDocling, built on Hugging Face’s SmolVLM, is a groundbreaking open-source document processing model that redefines document conversion. Packing 256M parameters into an end-to-end solution, it introduces DocTags, a universal markup format that not only captures content but also preserves structural information and spatial positioning.
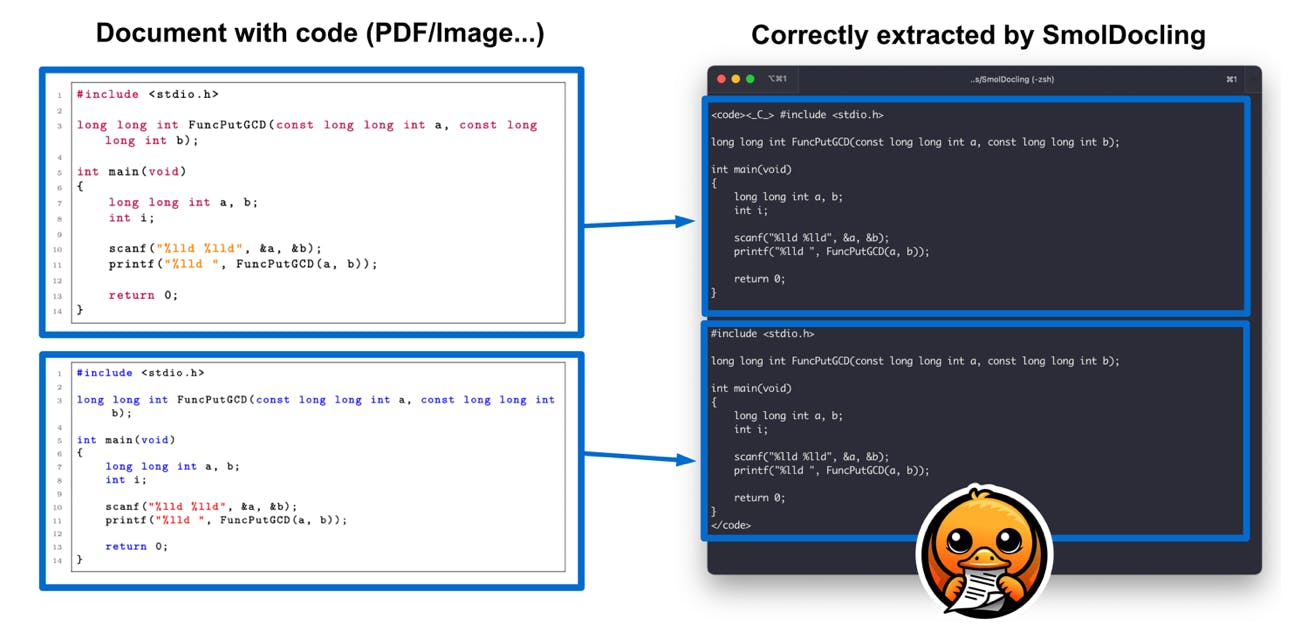
With its remarkable efficiency, SmolDocling accurately interprets and reproduces complex document features in a single step. Such features include code listings, tables, equations, charts, and lists, layout segmentation across diverse document types—including business reports, academic papers, patents, and structured forms.
Notably, it competes with Vision Language Models up to 27 times larger, while significantly reducing computational demands. Click here to see a demo of Smoldocling capabilities. In addition, the Smoldocling team is contributing new, publicly sourced datasets for charts, tables, equations, and code recognition to further advance open AI research. The model is already available, and the datasets will be released soon.
By March 27, 2025, SmolDocling became the #1 trending model on Hugging Face—one of the few small Vision Language Models (VLMs) to achieve this milestone! This success, driven by the AI Alliance mission, underscores the power of multi-stakeholder collaboration in developing and deploying open foundation models.
To continue this momentum, we invite the broader community of users and developers to contribute to Docling and SmolDocling by building new features, creating plug-in extensions, and enabling seamless integrations. Together, we can push the boundaries of open AI innovation!
There are three key ways to get involved:
- Create New Datasets – Contribute datasets for training or evaluation. We encourage you to use Docling to curate and share open datasets that can enrich the AI Alliance Open Trusted Data catalog and benefit the open-source community. We are particularly interested in high-quality, domain-specific, and reasoning datasets that support model tuning, application grounding, and enrichment.
- Develop Advanced Applications – Use Docling in increasingly sophisticated application scenarios across domains such as legal, materials science, semiconductors, and finance. Help expand its functionality by building new features and integration patterns. Join our Application and Tools Working Group in Focus Area 3
- Enhance SmolDocling Models – Contribute by developing new SmolDocling models tailored to your needs. Stay tuned for updates on open-source fine-tuning efforts!

Are you working on an open AI-driven project that could use a bigger stage? The AI Alliance is committed to helping you scale through visibility, collaboration, and support.
Join the movement. Build. Contribute. Collaborate. Innovate.
References: