
Write once, use anywhere—an open-source tool library for portable AI agents
The Problem: Framework Lock-In Wastes Time
If you’ve built and migrated AI agents, you’ve done this before:
- Write a tool for LangChain (e.g., a weather lookup).
- Switch to AWS Bedrock—now rewrite it.
- Try SmolAgents? Yep, rewrite it again.
This is inefficient. Most AI frameworks use similar underlying specs (like OpenAI’s function calling), but each has its own quirks. GoFannon fixes this by letting you write a tool once and export it to any framework.
How GoFannon Works
1. Standardized Tool Definitions
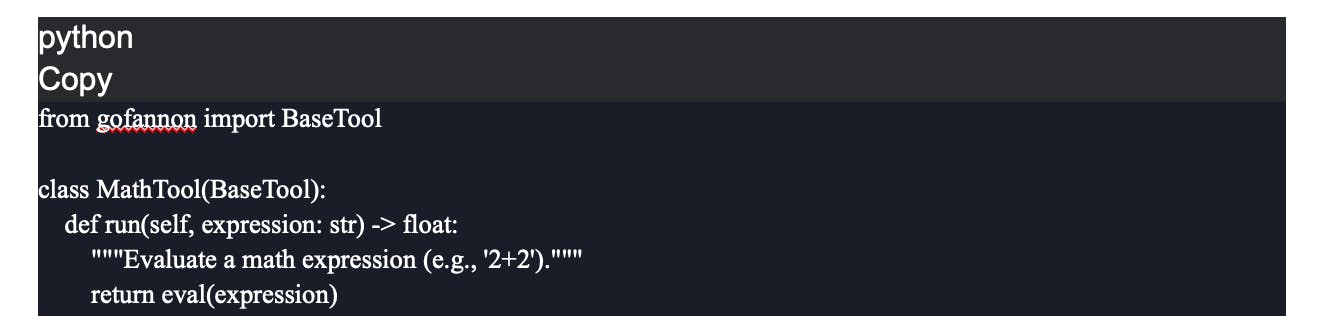
Every GoFannon tool inherits from BaseTool and defines:
- A definition (following OpenAI’s standards) for inputs/outputs.
- A fn() method with your core logic.
Example from the on of our example notebooks.
2. One-Line Framework Exports
Convert any tool to your framework of choice:

No rewrites. No boilerplate.
3. Pre-Built Tools
Gofannon includes production-ready tools, like:
- Wikipedia search
- Basic math operations
Why Developers Are Switching
✅ No More Duplicate Work
✅ Modular Install Only install what you need:

✅ Easy to Extend Adding a new tool or framework? We have curated guides.
How to Contribute (We Made It Simple)
GoFannon is built for open-source collaboration:
- Curated Developer Pathways
- Maintained list of ‘Good First Issue’ (Beginner)
- Documented path for creating and contributing tools (Intermediate)
- Documented path for creating and contributing new agentic frameworks
- Gamified Leaderboard
- PRs earn points (e.g., +500 for a new tool, +25 for a framework).
- Transparent Process
- ASFv2
Try It Now

Explore the docs:
Final Thought
AI frameworks will keep changing. Your tools shouldn’t have to.
Gofannon is by developers, for developers—no hype, just less redundant code.
Star the repo → Try it → Send a PR. Let’s fix this problem together. 🚀