
The Data Prep Kit (DPK) framework enables scalable data transformation using Python, Ray, and Spark, while supporting various data sources such as local disk, S3, and Hugging Face datasets. It defines abstract base classes for transformations, allowing developers to implement custom data and folder transforms that operate seamlessly across different runtimes. DPK also introduces a data abstraction layer to streamline data access and facilitate checkpointing. To support large-scale processing, it provides three runtimes: Python for small datasets, Ray for distributed execution across clusters, and Spark for highly scalable processing using Resilient Distributed Datasets (RDDs). Additionally, DPK integrates with Kubeflow Pipelines (KFP) for automating transformations within Kubernetes environments. The framework includes transform utilities, testing support, and simplified APIs for invoking transforms efficiently. By abstracting complexity, DPK simplifies development, deployment, and execution of data processing pipelines in both local and distributed environments.
In this blog post, we discuss the architecture of the Data Prep Kit (DPK) framework that is responsible for running data set transforms at scale, using either Python, including multiprocessing, Ray, or Spark, with support for accessing data on local disk, S3, Hugging Face datasets, etc. Kubeflow Pipelines (KFP) support is implemented for the automation of Transformation pipelines in Kubernetes, which will be discussed in a subsequent blog post.
NOTE: This post covers Data Prep Kit as of March 2025. Changes to the data access capabilities are under development. We’ll publish a follow up post when those changes become available.
Transforms
Transforms are the heart of DPK. DPK defines abstract base classes for transforms that require implementations to adhere to certain rules. Derived classes implement the desired transformations and DPK can process them generically, regardless of the implementation details.
Base transform classes
All of the transforms are derived from Abstract Transform. This is a fully abstract base class that is used as a marker for any derived class, indicating it is a transform implementation. DPK currently supports two types of transforms, data transforms and folder transforms.
Abstract Binary Transform is a base class for all data transforms, which converts one input file of data into zero or more output data files and metadata. When this base class is used, the following methods are implemented:
- transform_binary – a method that converts one input file into zero or more output files and metadata (see below for more details). The method arguments are the file name and a byte array containing the file data. The returned object is a tuple where the first element is a list of zero or more tuples, each of which contains an output file’s contents and the file’s name. The second tuple element is a dictionary of statistics that will be propagated to metadata storage.
- flush_binary – an optional method (a default implementation is provided) that can be used to implement transforms that store some of the input data internally (see, for example, Resize transform). In these non-default cases, this method supports returning some internal state.
A subclass of the binary transform is Abstract Table Transform, which consumes and produces PyArrow tables, simplifying the writing of transforms that process this data format. Similar to the Abstract Binary Transform, this class implements the following methods:
- transform – a method that is similar to transform_binary, but works with PyAarrow tables instead of arbitrary binary data. Additionally, this method validates that the output tables do not contain duplicate columns. If duplicates are found, an exception is thrown.
- flush – a method similar to flush_binary, but supporting PyArrow tables instead of arbitrary binary data.
Another subclass of the binary transform is an Abstract Folder transform, supporting the processing of folders of files, instead of individual files. In this case, a single method is implemented:
- transform – a method that takes the name of the folder and produces a tuple of a list of zero or more tuples (result files) and a dictionary of statistics that will be propagated to metadata storage. As for transform_binary above, each element of the result file tuple is a transformed byte array and a string for the name of the resulting file.
Support Transform classes
In addition to the base transform classes, the framework provides several transform support classes.
A Transform implementation typically requires some configuration. DPK separates configuration responsibilities into a separate class, Transform configuration. This separation of transform implementation and configuration allows for better maintainability of transform implementations. In addition to collecting parameters, this class can also implement parameter validation to determine whether parameters provided by the user are appropriate for a transform and stop execution if they are not.
For collecting overall statistics across multiple transform invocations, DPK provides the Transform statistics class that can sum up numeric statistics from multiple transform invocations.
The main classes of the Transform part of DPK are shown in Figure 1.
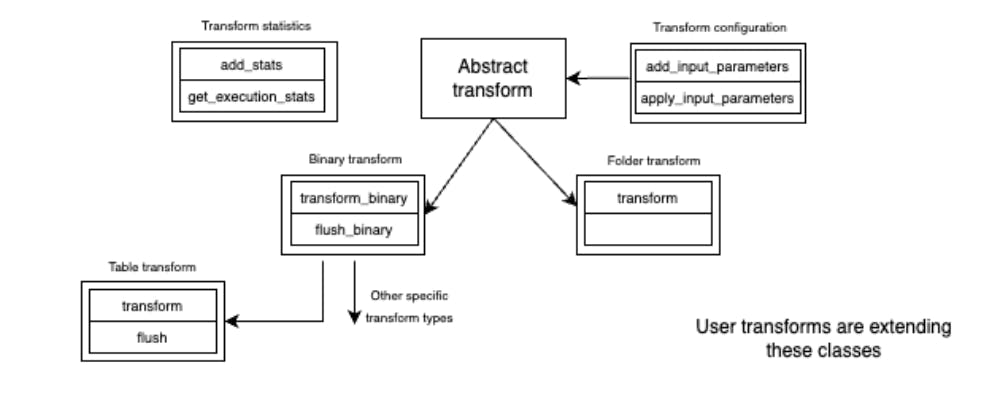
Figure 1 Main components of Transform
Data Access
For transforms to function correctly, they need to be able to read and write data. As data for transforms can come from disk, S3 compatible storage, Hugging Face Datasets, etc., DPK introduces a data abstraction layer that allows the framework to execute data operations generically, abstracting out details to derived classes for specific storage locations. The Data Access base class included in the framework provides an abstraction for common operations that are relevant to data processing, but not operations that are specific to particular storage locations. In addition to typical methods like file read/write, this class also provides a set of higher-level methods useful for data processing. For example, get_files_to_process, can retrieve all the files with a given extension from a source directory. It can also compare this list with the list of existing files in the destination directory and return back a list of only the files that exist in the source directory but not in the destination directory. This feature effectively supports checkpointing. If the current run fails and it is restarted, it will only process the files that have not been processed yet.
The current DPK implementation supports local disk access, using Data Access Local, S3 compatible data storage, using Data Access S3 and Hugging Face Datasets access using Data Access HF. Additional data access implementations are planned and they can also be implemented by users, as needed.
In order to specify a desired data storage location and configure it correctly, for example, to specify S3 credentials, source and destination folders, etc., the framework provides a Data Access Factory for specifying all supported parameters. Data access mechanisms can also be specified through a CLI. Data Access Factory also performs parameter validation, stopping execution if any of them are not valid.
The main classes of the data access layer are presented in Figure 2.
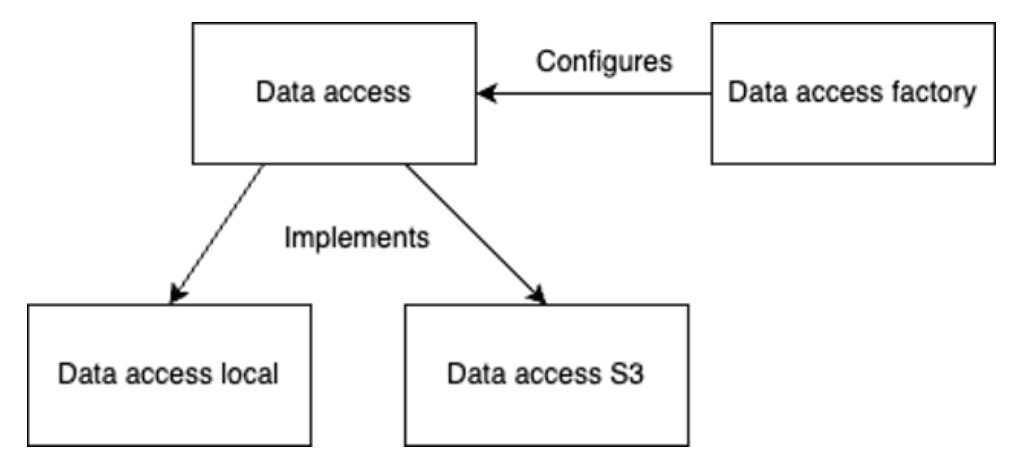
Figure 3 Data Access Layer
Transforms Utilities
To simplify the implementation of transforms, DPK provides a lot of utils, which are functions that implement common operations used in the transformers. We encourage users to browse these implementations and use them as much as possible for transformer implementations.
Transforms Processing
The default execution in DPK is implemented by the Transform File Processor. This class receives the file name, reads the file, executes the transform on the input data, stores the transform results at the desired locations (zero or more), and adds the transform’s execution metadata to the overall execution statistics. This means that the default processing in DPK is to run a given transform on all the input data, create the result files and then, if desired, to execute the next transform.
DPK Runtimes
DPK is designed for scalable processing of data, so it supports 3 different runtimes:
- Python, including multiprocessing support, for data set processing where a single machine is sufficient.
- Ray, including local and remote cluster support, for processing small to extremely large data sets.
- Spark, including local and remote cluster support, for processing small to extremely large data sets.
All the runtimes implement these basic classes, as shown in Figure 4.
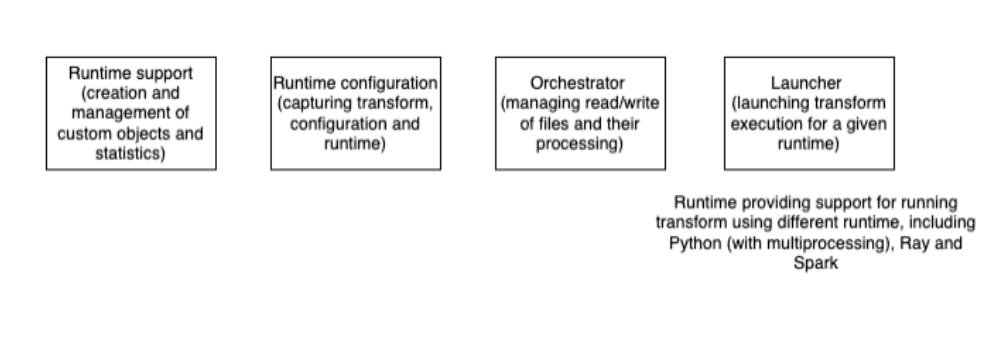
Figure 4 Basic runtime support
- The Runtime support class provides a place to create and clean up runtime-specific things, for example, shared objects in Python or supporting actors in Ray.
- The Runtime configuration class supports configuration of the execution runtime, for example, parallelism in Spark or executor resources in Ray.
- The Orchestrator class implements the sequence of actions necessary to run a transformer in the target runtime.
- The Launcher class provides support for launching a transform’s execution either programmatically or through a CLI.
We will describe each runtime in more detail below.
Python Runtime
The simplest runtime supported by DPK is Python. This runtime can be used if the amount of data is relatively small, it can fit onto a single computer, and the processing time is on the order of minutes to tens of minutes. The Python runtime can be used as a single process for sequential execution, in which case all the data items are transformed sequentially, or using Python multiprocessing, where requests are split between multiple Python processes. Switching between these two options is done by setting a configuration parameter, num_processors, in runtime configuration (no code changes are required).
NOTE: Some features, most notably shared state in memory, are not available when using Python multiprocessing. As a result, some of the built-in transforms, for example the ededup (exact deduplication) transform, will not work in the Python multiprocessing runtime.
To enable running a transform in the Python runtime, the following are required:
- If the transform needs a specific setup or postprocessing, implement the Transform Runtime class (see the ededup implementation for an example of how to do this). If the transform does not need this, then the default implementation will be used.
NOTE: One example for usage of the transform runtime is the case of transform initialization writing data to the local disk. When using the Python multiprocessing runtime and doing this initialization in the transform init method, then several processes can run this initialization in parallel, which can cause failures due to race conditions. Instead, if you do this initialization in the Transform runtime class, rather than instances, then it will be executed once and no race conditions will occur. Another example of transform runtime usage is creation of state that can be shared between transform executions.
- You need to implement Python runtime configuration which brings together the transform implementation, configuration, and runtime.
Once these two requirements are in place, you can invoke the Python launcher to specify parameters and execute the transform. The launcher will first invoke configurations for the transform, data access, and Python runtime, and then invoke the orchestrator to process individual files and/or folders.
Although the Python runtime works well for relatively small data sets that can be executed relatively quickly (minutes to tens of minutes) on a single machine, as the amount of data or transform computational complexity grows, the Python runtime can only scale vertically by increasing the size and power of the machine used for processing. To enable horizontal scaling to tens, hundreds, and even thousands of machines, use DPK support for one of two specialized frameworks, Ray and Spark.
Ray Runtime
Ray is an open-source unified framework for scaling AI and Python applications. It provides the compute layer for parallel processing so that users don’t need to be distributed systems experts. One of the fundamental features of Ray, which made it a very attractive platform for DPK, is its ability to scale from a laptop to a cloud with thousands of machines.
The two main Ray primitives, tasks and actors, enable Ray to flexibly support a broad range of distributed application patterns.
Ray enables arbitrary functions to be executed asynchronously on separate Python workers. These asynchronous Ray functions are called “tasks”. Ray enables tasks to specify their resource requirements for CPUs, GPUs, memory, and custom resources. These resource requests are used by the cluster scheduler to distribute tasks across the cluster for parallelized execution.
Actors extend the Ray API from functions (tasks) to classes. An actor is essentially a stateful worker (or a service). When a new actor is instantiated, a new worker is created, and methods of the actor are scheduled on that specific worker and can access and mutate the state of that worker. Like tasks, actors support CPU, GPU, memory, and custom resource requirements.
The DPK support for Ray leverages actors that perform parallel execution of transform file processors with associated transforms.
Similar to the Python runtime, to enable running a transform in the Ray runtime, you need to do the following:
- If your transform requires pre- or post-processing, you need to implement Transform Runtime (see the ededup implementation for the example of how this can be done). If your transform does not need this, then the default implementation will be used.
- You need to implement Ray runtime configuration, which brings together the transform, configuration, and runtime.
With these two requirements met, you can invoke the Ray launcher to specify parameters and execute the transform. The Launcher will first invoke configurations for the transform, data access, and Ray runtime, and then invoke the orchestrator to process the individual files and/or folders.
The Ray launcher includes an additional parameter, run_locally. When set to true, then a local Ray cluster will be created on the local machine for running the transform. If it is set to false, then the launcher will try to connect to the existing Ray cluster using the URL ray://localhost:10001
NOTE: Since the connection to the existing Ray cluster is done to localhost, it means that DPK assumes that this invocation runs on the head node of the cluster. When you run Ray on a Kubernetes cluster, trying to use a connection from a workstation outside of the cluster typically does not work, because this is an unsecured GRPC connection. So, when running a transform on Ray in a Kubernetes cluster, the following steps are required:
- Build a Docker image containing the Ray runtime, the transform, and all supporting libraries. Use a Dockerfile for every transform; see for example the ededup implementation.
- Create a Ray cluster using this Docker image.
- Log onto the head node of the cluster and start the Ray cluster, specifying run_locally to be false.
Although this manual approach will work, a better (simpler) way of running transforms on the Ray cluster is to use the Kubeflow Pipelines (KFP) approach included with DPK, which we will describe in a subsequent post.
Spark Runtime
Another popular distributed framework is Apache Spark - a multi-language engine for executing data engineering, data science, and machine learning scaling from single-node machines to clusters with hundreds to thousands of machines.
At its core, Apache Spark's architecture is designed for in-memory distributed computing. It can handle large amounts of data with remarkable speed. The key abstraction in Spark that is leveraged by DPK is the Resilient Distributed Data set (RDD).
Although RDD can contain all the data used by a transform, the DPK Spark implementation is designed to minimize the RDD size, and consequently the amount of data read by the Spark Master node. In the case of DPK, the RDD only contains the list of the files and/or folders that need to be processed, and the actual reading of the data as spread across workers, using transform file processors. This effectively means that we are using Spark purely as a distribution framework for executing transform file processor instances, which makes the overall implementation extremely fast and scalable.
Similar to Python and Ray runtimes, to enable running a transform in the Spark runtime, you need to do the following:
- If your transform requires pre or post-processing, you need to implement Transform Runtime (see the doc_id transform implementation for an example of how this can be done). If your transform does not need this, then the default implementation will be used.
- You need to implement the Spark runtime configuration, which brings together the transform, configuration, and runtime.
Once these requirements are met, you can invoke the Spark launcher to specify parameters and execute the transform. The launcher will first invoke configurations for the transform, data access, and Spark runtime and then invoke the orchestrator to process the files and/or folders.
This will execute the transform on the Spark cluster. To execute the transform on an external Spark cluster on Kubernetes (K8s), you can use Spark Operator, which aims to make specifying and running Spark applications as easy and idiomatic as running other workloads on Kubernetes. The operator uses Kubernetes custom resources for specifying, running, and surfacing the status of Spark applications.
Note that in order to use the Spark operator you will need to build a docker image containing the Spark runtime, your transform, and all supporting libraries. Use a Dockerfile for every transform, see for example doc_id.
Support for the Spark runtime is a relatively new addition to DPK and the support is less mature than for Python and Ray. Most importantly, additional enhancements in the usage of the Spark Operator and its integration with KFP are planned.
Transform Testing
DPK additionally provides some helper classes to simplify implementing tests for a transform. The base class of the testing support is Abstract test, containing various support functions generally useful for testing, for example, validate_expected_files, validate_expected_tables, etc.
This base class is used by Abstract Binary Transform Test and Abstract Table Transform Test, which support testing binary and table transform, respectively. Examples of their usage can be found in the code2parquet transform test (for binary data) and the ededup transform test (for table data).
The last test support class is Abstract Transform Launcher Test, which can be used for testing a transform using any runtime via the corresponding launcher. Examples of this class usage can be found in ededup Python and ededup Ray tests.
Simplified Invocation of Transforms
A typical transform invocation requires defining the transform parameters, passing them to sys.argv, and then invoking the runtime-specific launcher, along with the corresponding runtime configuration (see for example ededup Python invocation, ededup Ray invocation, etc.).
To make running transforms simpler, DPK introduced simplified APIs that eliminate the need of the majority of the boilerplate code. Currently, DPK provides two APIs for simplified transform invocation:
- Execute Python transform
- Execute Ray transform
- Execute Spark transform (coming soon)
Both API entry-point methods take the same argument lists and defer only in the function name, which embeds the name of the target runtime. They accept the following parameters:
- transform name
- transforms configuration object (see below)
- input_folder containing data to be processed, currently supporting local file systems or S3-compatible systems.
- output_folder defining where execution results will be placed, currently supporting local file systems or S3-compatible systems.
- S3 configuration, when using S3 input and/or output folders.
- transform params - a dictionary of transform-specific parameters.
The API returns true if the transform execution succeeds or false otherwise.
The implementation of the APIs leverages the Transforms Configuration class, which manages configurations of all existing transforms. By default, this class loads transform information from a json file, but it can be overridden by the user.
Finally, since the configurator knows about all existing transforms and their dependencies, it checks whether the transform code is installed locally and installs it using the Pip Installer class, if the code is not already installed. The transform code is removed after the transform execution is completed.
Summary
Implementing data processing is one of the most expensive activities in the creation of complex models. In addition to implementation of actual functionality of transforms, it is also necessary to ensure running of such implementation in highly distributed, scaled environments, including, for example multithreading Python (in the case of vertical scaling) or Ray and Spark (in the case of horizontal scaling). Data Prep Kit described in this blog post allows engineers to significantly simplify creation and maintenance of such processing pipelines by implementing all of the support required for running simple, Python-based implementations in highly scalable environments, both horizontally and vertically. The Python-based runtime also significantly simplifies creation of transforms by allowing local development, including debugging and testing them locally on a small dataset.
Additional support for multiple data locations allows engineers to change where data is read and written, without the need to modify the transformation code.