
As part of the Open Trusted Data Initiative, Pleias is releasing Common Corpus, the largest open and permissibly licenced dataset for training LLMs, at over 2 trillion tokens.
As part of the Open Trusted Data Initiative, Pleias is releasing Common Corpus, the largest open and permissibly licenced dataset for training LLMs, at over 2 trillion tokens. Open data – truly open data – is imperative for building safe and auditable models.
Common Corpus builds off recent initiatives, such as IBM’s Granite 3.0, for which all the data sources were openly announced. Common Corpus pushes boundaries of the open data landscape, by providing explicit provenance for each subcorpus. Common Corpus is:
- Truly Open: contains only data that is permissively licensed and provenance is documented
- Multilingual: mostly representing English and French data, but contains at least 1B tokens for over 30 languages
- Diverse: consisting of scientific articles, government and legal documents, code, and cultural heritage data, including books and newspapers
- Extensively Curated: spelling and formatting has been corrected from digitized texts, harmful and toxic content has been removed, and content with low educational content has also been removed.
Common Corpus makes it possible to train LLMs on truly open data, leading to auditable models and a more democratized LLM ecosystem. This new dataset meets the highest levels of compliance. By providing clear provenance and using permissibly licensed data, Common Corpus exceeds the requirements of even the strictest regulations on AI training data, such as the EU AI Act. Pleias has also taken extensive steps to ensure GDPR compliance, by developing custom procedures to enable personally identifiable information (PII) removal for multilingual data. This makes Common Corpus an ideal foundation for secure, enterprise-grade models. Models trained on Common Corpus will be resilient to an increasingly regulated industry.
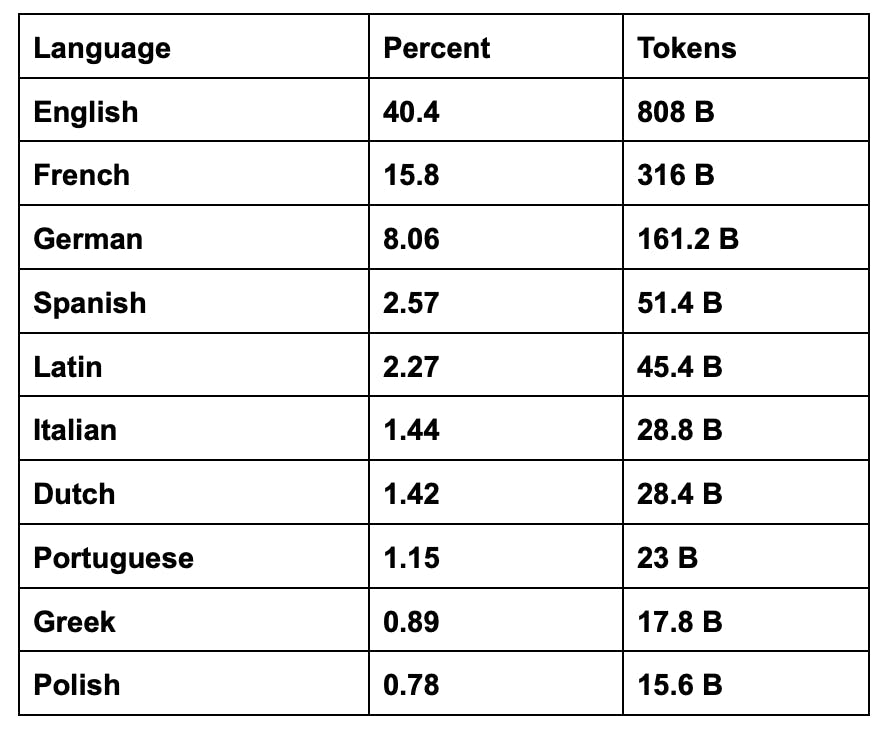
As it stands, open data is limited for English; however, even for relatively high-resource languages like French and German, the open data landscape is far worse. It is important to be developing datasets for a wide variety of languages to reduce the over-reliance of English in LLM development in order to broaden access and increase equity surrounding the economic benefits that accompany language technologies like LLMs. Common Corpus primarily contains English and French data, but there is a significant amount of data in German, Spanish, Italian, and other European languages.
Proportion of data in Common Corpus for each of the ten languages with the most data.
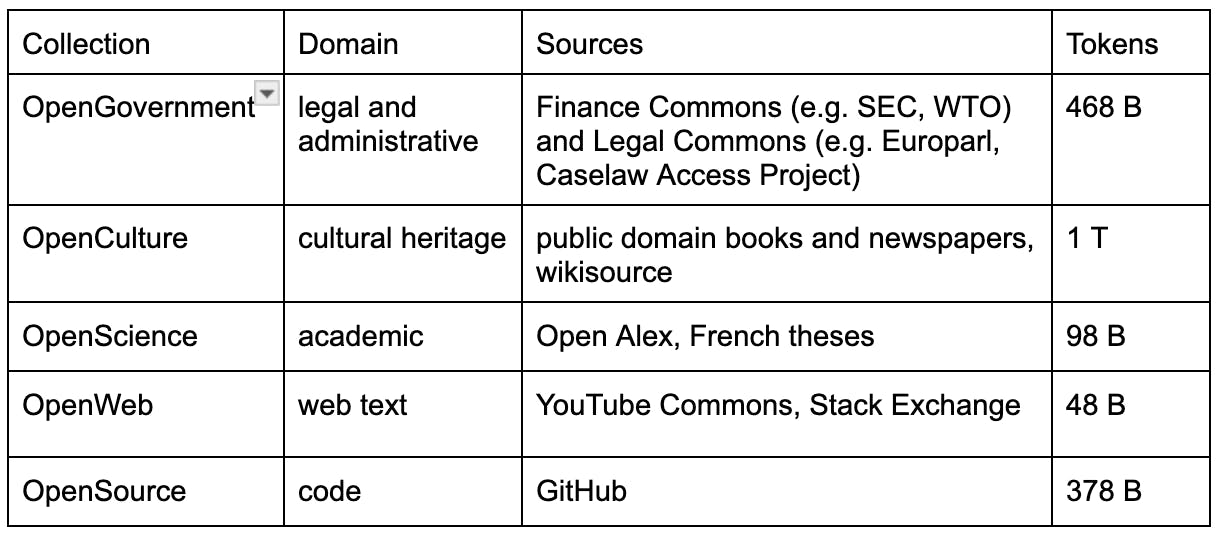
Data Provenance.
Common Corpus is composed of five main sub-corpora: OpenGovernment, OpenCulture, OpenScience, OpenWeb, and OpenSource. Each of these is distinct in style, content, and quality and comes from varied sources. The result is a diverse dataset suitable for training a general-purpose model.
OpenGovernment contains Finance Commons, a dataset of financial documents from a range of governmental and regulatory bodies. Finance Commons is a multimodal dataset, including both text and PDF corpora. OpenGovernment also contains Legal Commons, a dataset of legal and administrative texts. OpenCulture contains cultural heritage data like books and newspapers. Many of these texts come from the 18th and 19th centuries, or even earlier.
OpenScience data primarily comes from publicly available academic and scientific publications, which are most often released as PDFs. OpenWeb contains datasets from YouTube Commons, a dataset of transcripts from public domain YouTube videos, and websites like Stack Exchange. Finally, OpenSource comprises code collected from GitHub repositories which were permissibly licensed.
High-Quality Data Curation.
Ensuring high data quality is important as it has been shown to positively impact model performance. Curation for Common Corpus is unlike that for web data like Common Crawl, which primarily entails deduplication and text quality filtering. There are well-established tools and procedures for this, especially for English, for which there is the most web data. Pleias has taken an individualized approach to curating each dataset, as there is no one-size-fits-all solution to ensuring high-quality training data. Each sub-corpus in Common Corpus was filtered and curated using a different combination of procedures.
OpenCulture required multiple curation steps. First was correcting digitization errors. Most of these texts were scanned and digitized with Optical Character Recognition (OCR), which often leaves mistakes and unwanted digitization artifacts. Pleias created a suite of custom tools for this dataset, including an OCR correction model, OCRonos-Vintage, which Pleias trained from scratch and have made publicly available. At 124 million parameters, it runs on CPU and GPU. As a small model, it has an extremely high throughput, making it efficient when running at scale. It is able to accurately fix incorrect spacing, replace incorrect words, and generally correct broken text structures. This step is essential for using data that is the result of public digitization efforts, which were the source of most of the cultural heritage data.
As the OpenCulture texts are mainly historical, some of the texts contain toxic or harmful content, because social norms have changed drastically, especially surrounding language used to describe minoritized groups. Pleias developed a pipeline for reducing the amount of toxic content in the dataset, which is described in a recently published preprint about, where there is expanded discussion about the motivation and method used. The key component of the pipeline is the toxicity classifier developed to specifically handle the unique features of the dataset: historical, multilingual data with OCR errors. Pleias also released the training data and the code for the classifier. To curate OpenCulture, toxicity ratings from the classifier to identify extremely harmful content and then it was removed or transformed via synthetic rewriting. The resulting dataset has a greatly reduced potential for societal harm, while not compromising textual quality or dataset size. This is an ongoing research area at Pleias, with the goal of continuing to develop safe and fair models and datasets.
Datasets derived from PDF, such as the data in OpenScience, were not created by simply extracting plain text, as this loses important contextual and stylistic information about the structure of the text, such as headings. Instead, using a vision-language model (VLM), the structure and layouts of the PDFs were parsed, then the text was extracted in a way that is sensitive to the layout and formatting of each document.
The natural language data was filtered for quality similar to the approach used by FineWeb, where content with low educational content was removed. For the code dataset, however, there was a multi-step approach. First, key programming languages were identified. Files in other programming languages and data files were removed. Then code segments were annotated using an existing tool, ArmoRM, which uses features such as complexity, style, and explanation to score code quality. All code that fell below the 20th percentile in quality rating was removed.
Data for Key Capabilities.
The resulting dataset is unlike other open datasets, which are composed in large part of web data. Common Corpus is composed of books, newspapers, scientific articles, government and legal documents, code, and more. This can help develop models which have generalizable capabilities for a wide variety of tasks. For example, the inclusion of scientific and legal documents is intended to increase world knowledge of LLMs trained on this corpus and increase factual outputs. Code data can be used not only to train code-generation models, but has been shown to improve reasoning capabilities for natural language generation.
In terms of developing models with users in mind, Common Corpus is well-suited to train models for creative composition. In an analysis of one million user interactions with ChatGPT, researchers found that 30% of user requests related to generating creative writing, including fictional story or poetry generation. However, training on creative writing data, such as book text, is difficult, primarily due to legal reasons. Some of the largest AI industry players have been sued for their unauthorized use of books and journalistic material that is protected by copyright. One of the largest open book corpora, Books3, was taken down by anti-piracy groups, making the availability of creative writing content even more limited. OpenCulture contains significant numbers of books and periodicals in at least ten languages, all of which are in the public domain. This allows for the legal training of LLMs to generate creative texts in a variety of languages. Furthermore, as context windows are growing larger, long-context data will increasingly be the bottleneck for developing powerful language models. Book data in OpenCulture are well-suited to this.
Common Corpus also includes multimodal data. PDFs from administrative or academic domains contain rich structured data and high-quality text. These multimodal data allow for the development of practical tools and applications for document processing, which have applications for administrative contexts, but also lead to the development of more and better datasets.
Common Corpus contributes to the growing ecosystem of open datasets, including Dolma from Ai2 and FineWeb from HuggingFace. Common Corpus diversifies the languages and domains represented in the open data landscape, which helps everyone train better models. The complete dataset is available on HuggingFace: at https://huggingface.co/datasets/PleIAs/common_corpus. Pleias is also releasing a complete technical report, describing the full details about the curation and filtering procedures used, as well as the complete provenance of all of the data. Additionally, the sub-corpora will be released individually in the coming weeks.