We conducted a survey with 100 AI Alliance members to learn about the state of open source AI trust and safety for 2024. This blog post highlights key findings on AI applications, model popularity, safety concerns, regulatory focus, and gaps in current safety practices, while also providing an overview of notable open-source projects, tools, and research in the field of AI trust and safety.
Contributors: Joe Spisak (Meta), Andrea Greco (IBM Research), Zhuo Li (HydroX AI), Florencio Cano (Red Hat), Victor Bian (HydroX AI), Kristen Menou (University of Toronto), Virendra Mehta (University of Trento), Dean Wampler (IBM Research), Jonathan Bnayahu (IBM Research), Zach Delpierre Coudert (Meta), Agata Ferretti (IBM Research)
The AI Alliance now has more than 140 members in 23 countries and is growing. Membership is diverse with 35% start-ups, 30% academic organizations, 19% enterprises, 11% non-profits and 6% research institutions. This diversity of perspective is an absolute strength of the Alliance and it’s been exciting to witness its growth over the last year.
One of the six Alliance workstreams led by Meta and IBM has been focused on trust and safety and how we can bring people together to tackle some of the major challenges faced by the community today. Inspired by the State of AI Report led by Air Street Capital and Nathan Benaich, we thought it would be interesting to dive deeper in this area and build an understanding of the ground truth for AI Alliance members regarding:
- What best practices are being applied today including tools, evals and methodologies?
- What major gaps exist?; and
- What are the top needs and wants from developers in this space?
We conducted a survey of AI Alliance member organizations and received 110 responses. We hope that this post will help bridge the gap between platform providers, model developers and ultimately those building generative AI applications to help drive the community towards a direction that benefits us all.
Key takeaways:
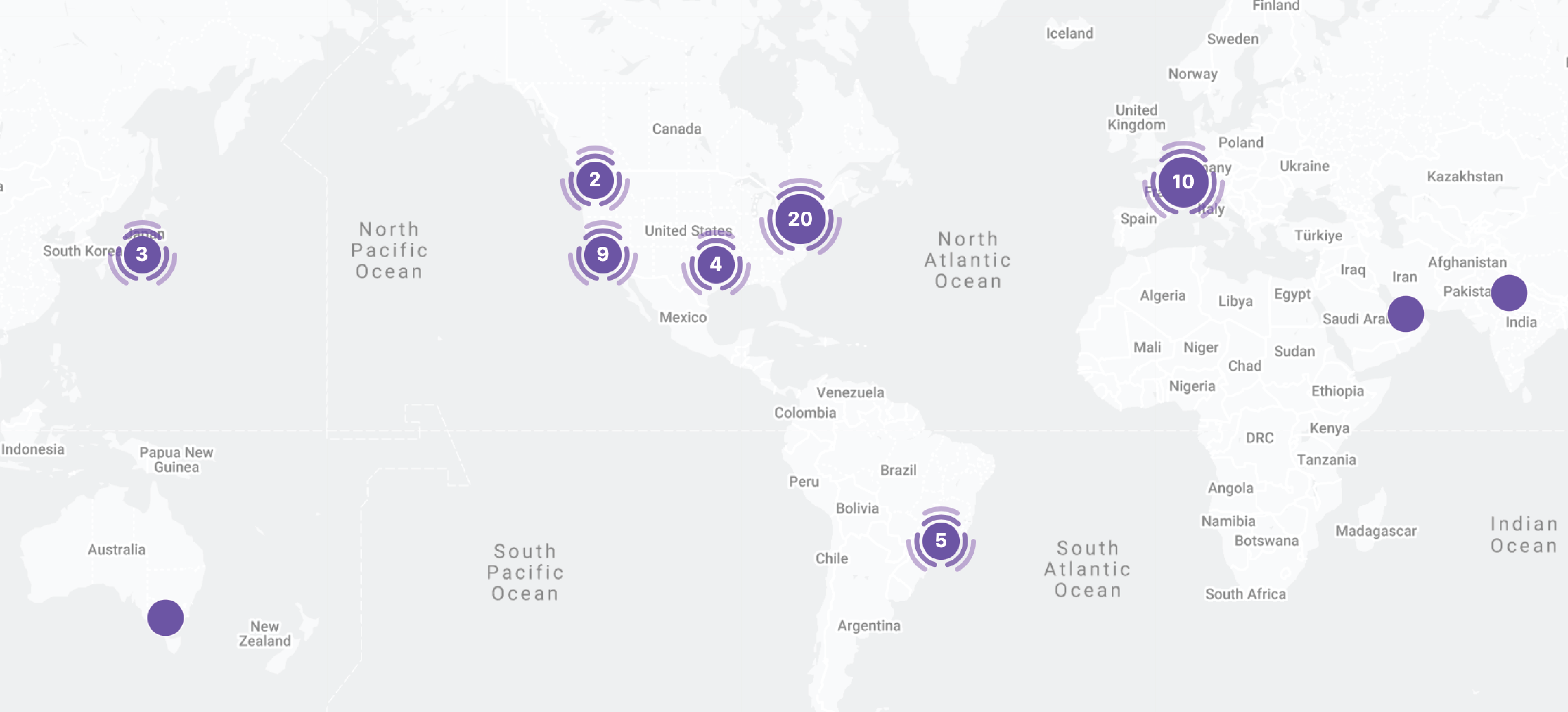
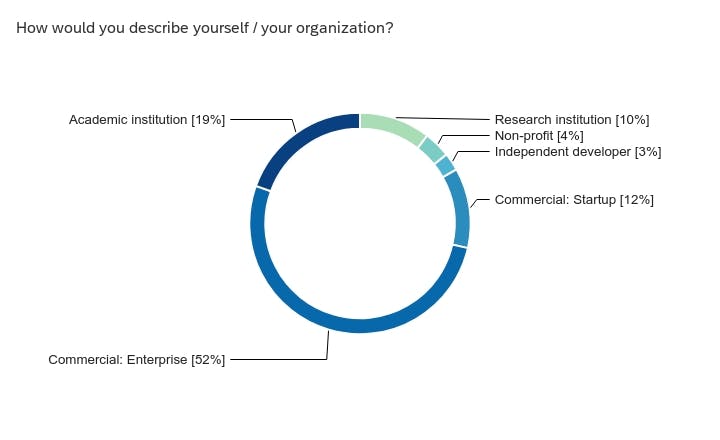
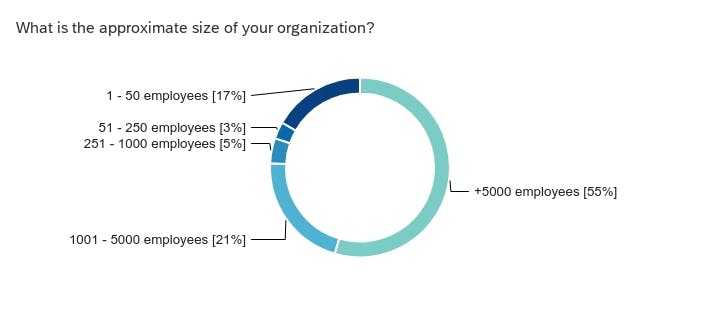
- Respondents: The largest segment of survey takers (~50%) are from enterprises followed by academia, then an almost equal split between research and start-ups, and independent developers and non-profits closing it out. The majority of the respondents are from the United States, then Europe, Brazil, South Korea, Australia, India and UAE.
- Applications: Chatbots, coding assistants and summarization were the main use cases deployed today.
- Model popularity: GPTx and Llama topped the list followed by Mistral and a very long tail of other models.
- Importance of safety: On average respondents reported that it was very high (~8 out of 10) as a critical concern for their applications. These concerns are motivated by legal, regulatory and customer satisfaction (in that order) with some driven by competitive pressures.
- Regulations: The EU AI Act is the core regulation on the minds of the survey takers regardless of the region they are from.
- Source of AI Safety knowledge: Mainly driven by internal teams, NIST with some leveraging AI specific safety vendors and cloud providers.
- Use case risk: Running counter to many narratives, 2/3rds of respondents have not seen use cases that were too risky to deploy.
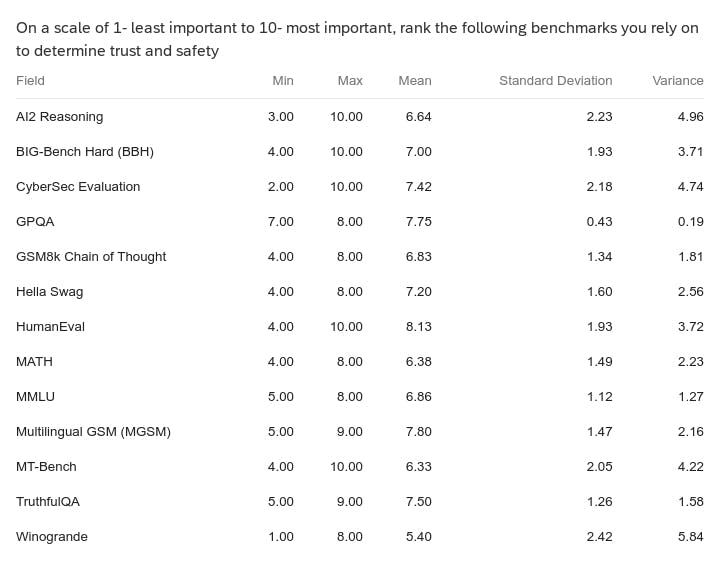
- Top Gap: The community still does not trust the current benchmarks and upvoted better safety evals as the top request followed by auto red-teaming and better guardrails. No surprises here!!
The Voice of the Community
To get a deeper understanding, we surveyed AI Alliance members across a number of areas - including motivations and operating models; tools and evaluations; and what major gaps exist today.
The following questions were posed in the survey. Please note N=110. Survey questions with a single select option are represented by a donut chart and multiple select options are represented by a bar chart.
About the survey taker

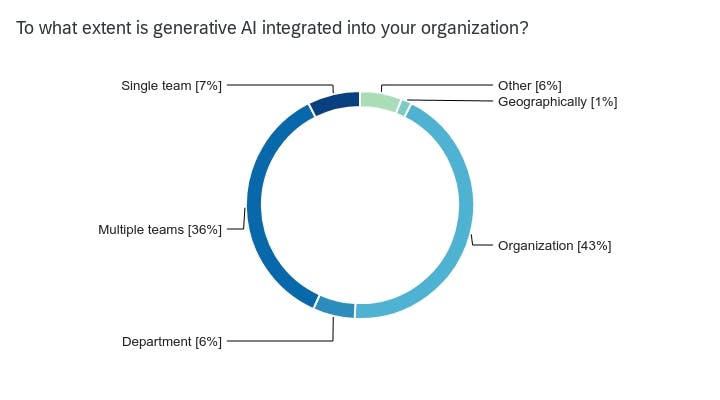
Usage and adoption
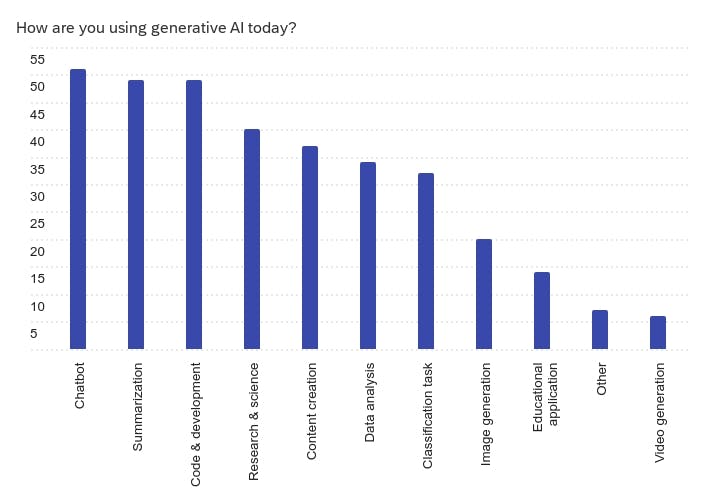
Other uses of generative AI include safety and controls such as evaluations and guardrail technology and synthetic data generation.
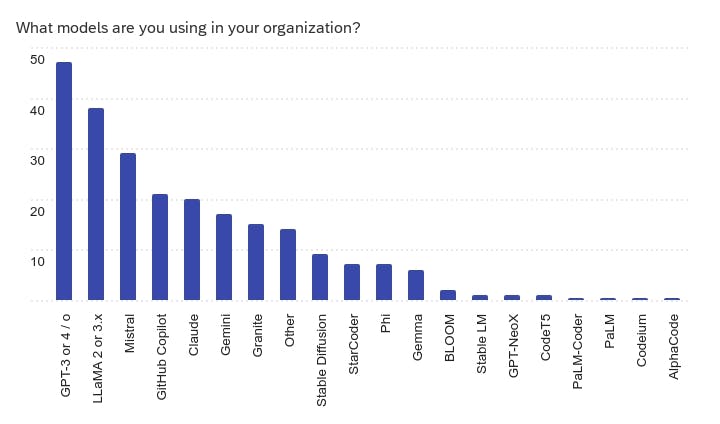
Other models being used include Codestral, Command, DeepSeek, Falcon, Jais, Mellum, and Tabnine.
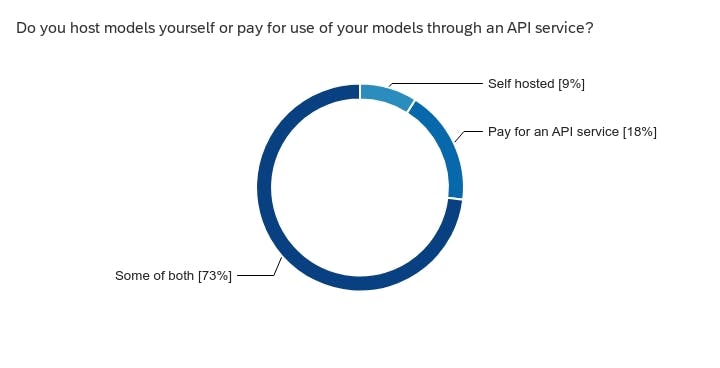
Motivations & Operating Model


The regulations identified include the EU AI Act, with others such as GDPR, FERPA, FinCrime, HIPAA, and others.
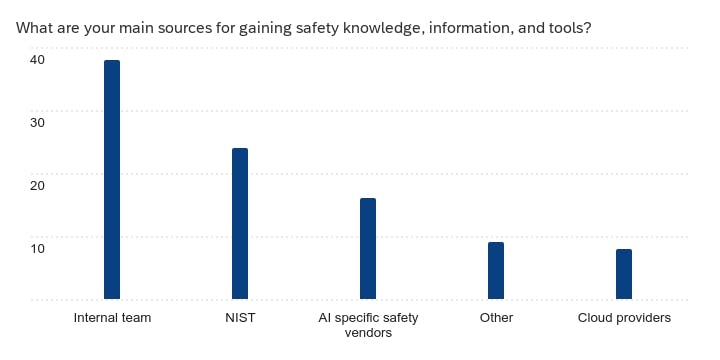
Other noted sources of safety and trust information include research and DEFCON.
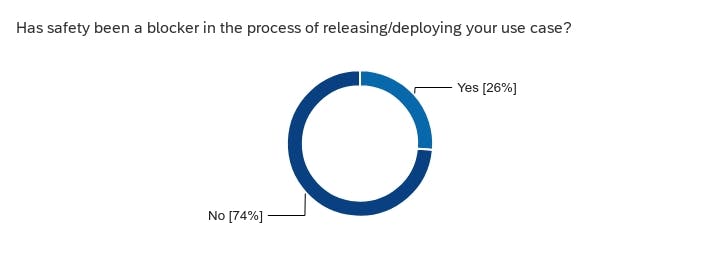
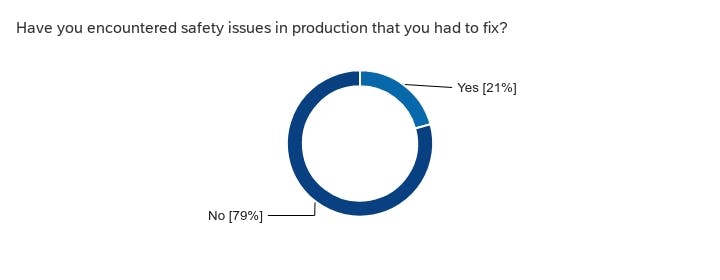
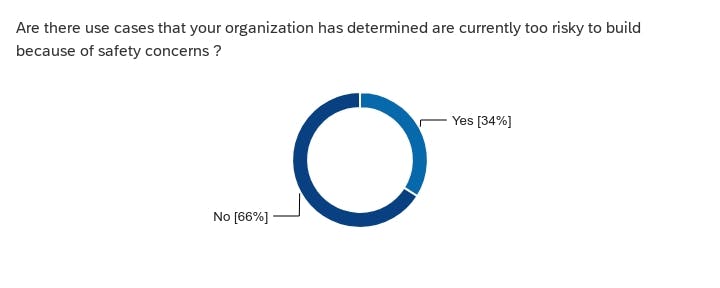
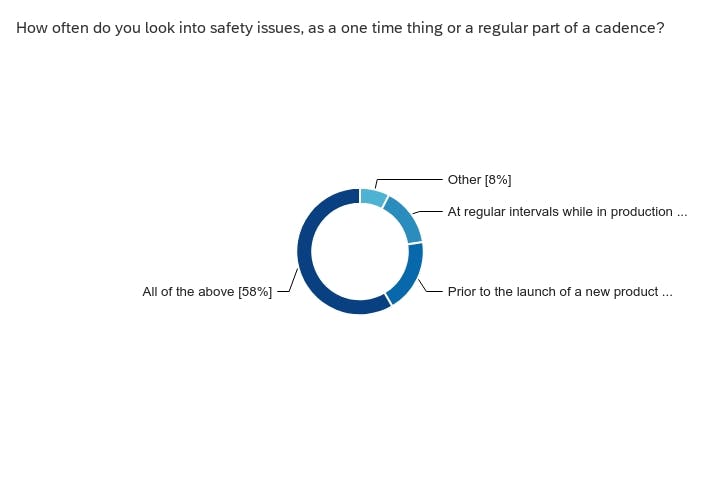
Tools and evaluations
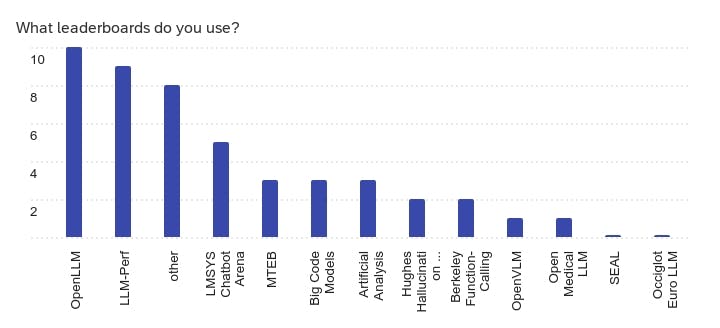
Other leaderboards noted include W&B Nejumi LLM and home grown leaderboards.
Other tools used include Citadel Lens, Granite Guardian, homegrown internal tools, and LibrAI.
Market gaps
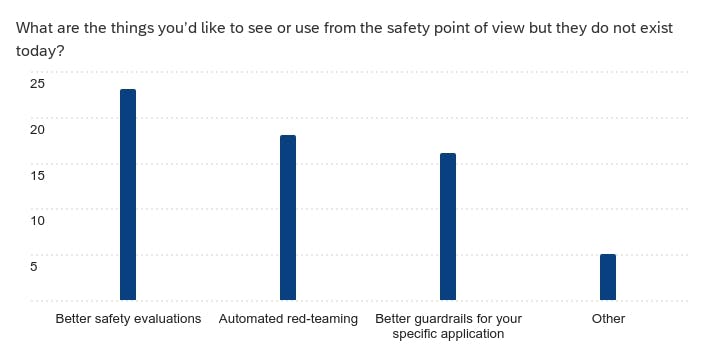
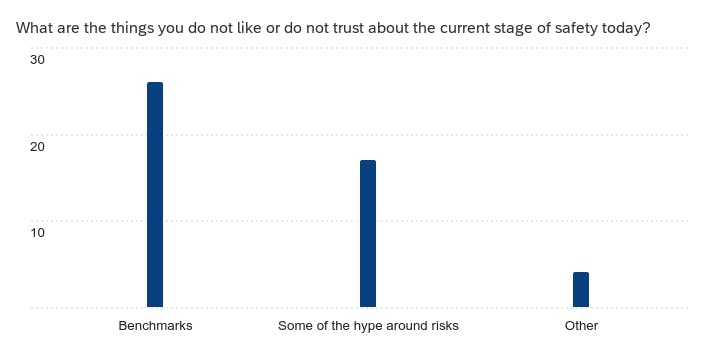
We ended by asking our fellow Alliance members what we didn’t ask them in the survey, but should have. Here is a summary of responses:
- Autonomous agents
- Data and supply chain trustworthiness
- Enterprise AI and systemic risk
- Use case evaluation
Interesting open source projects, models, and evals...
In addition to the survey, we also looked across the ecosystem to see what was trending. While open LLMs have continued to be released by industry and startups including Granite, Mistral, Llama, Gemma, Phi and many others, safety has been less of a focus. Here is a brief survey of what we’ve seen in the community but please reach out if you know of other great projects to include and we’d be happy to update!
Open source guardrails
NeMo-Guardrails: NeMo Guardrails is an open-source toolkit for easily adding programmable guardrails to LLM-based conversational applications. Guardrails (or "rails" for short) are specific ways of controlling the output of a large language model, such as not talking about politics, responding in a particular way to specific user requests, following a predefined dialog path, using a particular language style, extracting structured data, and more.
Llama Guard: Llama Guard models consist of a series of high-performance input and output moderation models designed to support developers to detect various common types of violating content. The latest versions filter both image input and text input/outputs in multiple languages.
Prompt Guard: Prompt Guard is a classifier model trained on a large corpus of attacks, capable of detecting both explicitly malicious prompts as well as data that contains injected inputs. The model is useful as a starting point for identifying and guardrailing against the most risky realistic inputs to LLM-powered applications; for optimal results we recommend developers fine-tune the model on their application-specific data and use cases.
Granite Guardian: A collection of models designed to detect risks in user prompts and LLM responses, along the risk dimensions catalogued in IBM’s AI Risk Atlas.
CodeShield: CodeShield is a robust inference time filtering tool engineered to prevent the introduction of insecure code generated by LLMs into production systems.
ShieldGemma: A series of safety classifiers, trained on top of Gemma 2, for developers to filter inputs and outputs of their applications.
Guardrails AI: Guardrails is a Python framework that helps build reliable AI applications by running Input/Output Guards in your application that detect, quantify and mitigate the presence of specific types of risks
Garak: checks if an LLM can be made to fail in a way we don't want. Garak probes for hallucination, data leakage, prompt injection, misinformation, toxicity generation, jailbreaks, and many other weaknesses.
Roblox’s Voice Safety Classifier: checks for voice toxicity and classification trained on a manually curated real-world dataset. The model weights either by downloading from from HuggingFace under roblox/voice-safety-classifier
PII Masker: a Python tool designed to identify and mask Personally Identifiable Information (PII) in text using a pre-trained NLP model based on the DeBERTa-v3 architecture.
Safety measurement & benchmarking
TrustyAI: TrustyAI is, at its core, a Java library and service for Explainable AI (XAI). TrustyAI offers fairness metrics, explainable AI algorithms, and various other XAI tools at a library-level as well as a containerized service and Kubernetes deployment.
Unitxt: Unitxt is a Python library for textual data preparation and evaluation of generative language models. It deconstructs the data preparation and evaluation flows into modular components, enabling easy customization and sharing between practitioners. Unitxt is an AI Alliance Affiliated Project.
Attaq, ProvoQ, and SocialStigmaQA: Red-teaming and social bias evaluation datasets.
BenchBench: a Python package designed to facilitate benchmark agreement testing for NLP models. It allows users to easily compare multiple models against various benchmarks and generate comprehensive reports on their agreement. A safety-oriented version of BenchBench is deployed on the AI Alliance space, as SafetyBAT.
Lm-evaluation-harness: This project provides a unified framework to test generative language models on a large number of different evaluation tasks and is the backend for 🤗 Hugging Face's popular Open LLM Leaderboard, has been used in hundreds of papers, and is used internally by dozens of organizations including NVIDIA, Cohere, BigScience, BigCode, Nous Research, and Mosaic ML.
Project Moonshot: Developed by the AI Verify Foundation, Moonshot is one of the first tools to bring Benchmarking and Red-Teaming together to help AI developers, compliance teams and AI system owners evaluate LLMs and LLM applications.
Giskard: Giskard is an open-source Python library that automatically detects performance, bias & security issues in AI applications. The library covers LLM-based applications such as RAG agents, all the way to traditional ML models for tabular data.
CyberSec Evaluation: CyberSecEval 3 is an extensive benchmark suite designed to assess the cybersecurity vulnerabilities of Large Language Models (LLMs). Building on its predecessor, CyberSecEval 2, this latest version introduces three new test suites: visual prompt injection tests, spear phishing capability tests, and autonomous offensive cyber operations tests. Created to meet the increasing demand for secure AI systems, CyberSecEval 3 offers a comprehensive set of tools to evaluate various security domains. It has been applied to well-known LLMs such as Llama2, Llama3, codeLlama, and OpenAI GPT models. The findings underscore substantial cybersecurity threats, underscoring the critical need for continued research and development in AI safety.
Detoxify: Trained models & code to predict toxic comments on 3 Jigsaw challenges: Toxic comment classification, Unintended Bias in Toxic comments, Multilingual toxic comment classification. Built by Laura Hanu at Unitary, where they are working to stop harmful content online by interpreting visual content in context.
MLCommons AILuminate: a community based effort focused on: 1) Curate a pool of safety tests from diverse sources; 2) Defining benchmarks for specific AI use-cases, each of which uses a subset of the tests and summarizes the results in a way that enables decision making by non-experts; and 3) Developing a community platform for safety testing of AI systems that supports registration of tests, definition of benchmarks, testing of AI systems, management of test results, and viewing of benchmark scores.
DecodingTrust: comprehensive and unified evaluation platform dedicated to assessing the trustworthiness of LLMs.
RedArena: Part of the LMSys effort, RedTeam Arena provides a time bound gamified platform for red teamers to attempt to jailbreak models. HydroX AI safety community: periodically publishes the latest safety ranking of both open-source and closed-source models. Results are based on evaluation across 30+ safety categories (e.g. bias) and 20+ advanced jailbreaks (e.g. AutoDAN). Its affiliated community, Silicon Wall-E, provides a gamified LLM jailbreak experience for public awareness.
Interesting research
Research in AI Trust and Safety is an incredibly broad area. While we can’t cover the field in its entirety, we’d like to share some of the more interesting work as sourced from members of the trust and safety working group.
Open-sourced safer models: enhanced models from open source ones that are 2-5X safer and no performance loss compared with the original evaluation. An initial paper talking about how this works:
Precision knowledge editing: Enhancing Safety in Large Language Models (Xuying et al.)
We hope you enjoy the papers!
Surveys
- Towards Safer Generative Language Models: A Survey on Safety Risks, Evaluations, and Improvements (Deng et al.)
- AI Safety in Generative AI Large Language Models: A Survey (Chua et al.)
- Foundational Challenges in Assuring Alignment and Safety of Large Language Models
- International Scientific Report on the Safety of Advanced AI
- Evaluating AI Evaluation: Perils and Prospects
Benchmarks
- Do These LLM Benchmarks Agree? Fixing Benchmark Evaluation with BenchBench. (Perlitz et al.)
- Efficient Benchmarking of Language Models (Perlitz et al.)
Adversarial & red teaming
- In-Context Learning-related risks: Many-Shot Jailbreaking
- Open-weight LLMs can in principle be safety-reinforced: Tamper-Resistant Safeguards for Open-Weight LLMs
- AutoDAN-Turbo: a lifelong agent for strategy self-exploration to jailbreak LLMs
- Code injection attacks via images on Gemini Advanced (Xuying et al.)
What's next?
- The AI Alliance Trust and Safety Evaluations project is defining a reference stack for all kinds of evaluations measured both at inference time and offline for benchmarks used for model and application development. We are also expanding the taxonomy of evaluations people might want to do, such as areas of performance and alignment beyond safety, with hosted dashboards for key areas of interest. We invite you to join us.
- On a bi-weekly basis we host the AI Alliance Trust and Safety working group members to connect and learn about each other’s work. If you would like to attend and present your work or work that you find interesting. Please reach out!
Cheers,
Team AI Alliance - Trust & Safety